Loading problems...
TL;DR: The optimal solution utilizes a 2D Dynamic Programming table to iteratively calculate the length of the longest common subsequence for every pair of prefixes, achieving a deterministic polynomial time complexity.
The Longest Common Subsequence problem asks us to find the length of the longest sequence of characters that appears in the same relative order in two given strings, text1 and text2. Unlike substrings, subsequences do not need to be contiguous; however, the relative order of characters must be preserved. For example, "ace" is a subsequence of "abcde".
This is a fundamental computer science problem often used in diff tools and bioinformatics. The LeetCode 1143 Solution requires finding the maximum length efficiently, avoiding the exponential costs associated with naive comparisons.
The brute force strategy attempts to explore every possible subsequence combination. This is typically implemented via simple recursion.
We can define a recursive function solve(i, j) that returns the LCS length for text1 starting at index i and starting at index .
text2jtext1[i] equals text2[j], we assume this character is part of the LCS and add 1 to the result of solve(i+1, j+1).text1 and calculate solve(i+1, j).text2 and calculate solve(i, j+1).Pseudo-code:
textfunction solve(i, j): if i == length(text1) or j == length(text2): return 0 if text1[i] == text2[j]: return 1 + solve(i + 1, j + 1) else: return max(solve(i + 1, j), solve(i, j + 1))
Time Complexity Analysis: The time complexity is , where and are the lengths of the strings. In the worst case (e.g., no matching characters), the recursion tree branches twice at every step, leading to exponential growth.
Why it fails:
For string lengths up to 1000 (as per the constraints), is astronomically large. This approach essentially re-solves the same subproblems (e.g., solve(5, 5)) millions of times, leading to a Time Limit Exceeded (TLE) error.
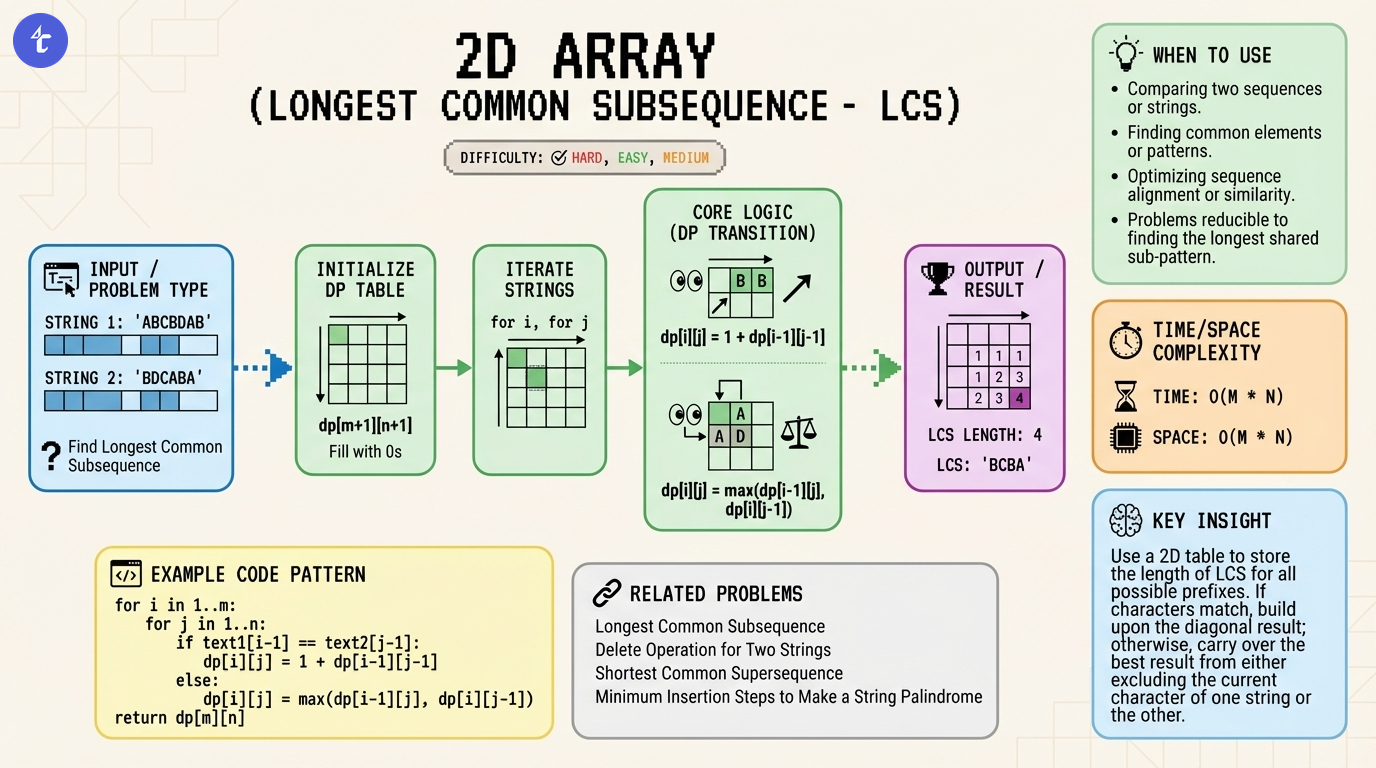
The key intuition is that the decision at any pair of indices (i, j) depends entirely on the results of the immediate previous states. We can construct the solution bottom-up (or top-down with memoization) by filling a 2D grid where dp[i][j] represents the LCS of the prefix text1[0...i-1] and text2[0...j-1].
The transition logic relies on a specific invariant:
text1[i] and text2[j] match, they must contribute to the LCS. We extend the LCS found for the prefixes ending before i and j. Geometrically, this looks like taking the value from the top-left diagonal cell and adding 1.text1) or the cell directly to the left (excluding current char of text2).Visual Description:
Imagine a grid where rows represent characters of text1 and columns represent characters of text2. We fill this grid row by row. When we are at cell (i, j), we look at three neighbors: top, left, and top-left.
State Definition:
Create a 2D array dp of size (m + 1) x (n + 1), where m and n are the lengths of text1 and text2.
dp[i][j] stores the length of the Longest Common Subsequence between the first i characters of text1 and the first j characters of text2.
Initialization:
Initialize the first row and first column with 0. This represents the base case: the LCS of any string and an empty string is 0. This padding simplifies index management.
Iteration:
Iterate through the grid using nested loops: i from 1 to m, and j from 1 to n.
State Transition:
Inside the loop, compare text1[i-1] and text2[j-1] (adjusting for 0-based indexing of strings vs 1-based indexing of DP table).
text1[i-1] == text2[j-1]:
dp[i][j] = 1 + dp[i-1][j-1]text1[i-1] != text2[j-1]:
dp[i][j] = max(dp[i-1][j], dp[i][j-1])Result:
The value at dp[m][n] contains the length of the LCS for the complete strings.
Let's trace text1 = "ace", text2 = "abcde".
DP Table size: 4 x 6. Initialized with 0s.
dp[1][1] = 1 + dp[0][0] = 1.dp[1][2] = max(dp[0][2], dp[1][1]) = max(0, 1) = 1.dp[2][3] = 1 + dp[1][2].dp[1][2] was 1 (from the 'a' match). So dp[2][3] = 2.dp[3][5] = 1 + dp[2][4].dp[2][4] carried over the value 2. So dp[3][5] = 3.Final result at dp[3][5] is 3 ("ace").
The correctness relies on the principle of optimality.
For any two prefixes S1 and S2:
x == y), then the LCS must include this character. The problem reduces to finding the LCS of S1 without x and S2 without y. If we didn't include x, we would be wasting a matching pair, which contradicts the goal of finding the longest subsequence.x != y), the LCS cannot end with a match at this exact position. The LCS must be formed either by ignoring x (solution lies in LCS(S1-x, S2)) or ignoring y (solution lies in LCS(S1, S2-y)). Since we want the maximum length, taking the max of these two subproblems covers all valid possibilities.
By induction, since the base cases (empty strings) are correct, and every step makes a locally optimal choice based on correct sub-results, the final result is globally optimal.cppclass Solution { public: int longestCommonSubsequence(string text1, string text2) { int m = text1.length(); int n = text2.length(); // dp[i][j] stores the LCS length of text1[0...i-1] and text2[0...j-1] vector<vector<int>> dp(m + 1, vector<int>(n + 1, 0)); for (int i = 1; i <= m; ++i) { for (int j = 1; j <= n; ++j) { // If characters match, extend the diagonal result if (text1[i - 1] == text2[j - 1]) { dp[i][j] = 1 + dp[i - 1][j - 1]; } // If mismatch, carry over the max from top or left else { dp[i][j] = max(dp[i - 1][j], dp[i][j - 1]); } } } return dp[m][n]; } };
javaclass Solution { public int longestCommonSubsequence(String text1, String text2) { int m = text1.length(); int n = text2.length(); // dp[i][j] represents the LCS of text1.substring(0, i) and text2.substring(0, j) int[][] dp = new int[m + 1][n + 1]; for (int i = 1; i <= m; i++) { for (int j = 1; j <= n; j++) { // Check characters (adjust for 0-based indexing) if (text1.charAt(i - 1) == text2.charAt(j - 1)) { dp[i][j] = 1 + dp[i - 1][j - 1]; } else { dp[i][j] = Math.max(dp[i - 1][j], dp[i][j - 1]); } } } return dp[m][n]; } }
pythonclass Solution: def longestCommonSubsequence(self, text1: str, text2: str) -> int: m, n = len(text1), len(text2) # Initialize (m+1) x (n+1) grid with zeros dp = [[0] * (n + 1) for _ in range(m + 1)] for i in range(1, m + 1): for j in range(1, n + 1): # Compare characters corresponding to current dp index if text1[i - 1] == text2[j - 1]: dp[i][j] = 1 + dp[i - 1][j - 1] else: dp[i][j] = max(dp[i - 1][j], dp[i][j - 1]) return dp[m][n]
Time Complexity: We fill a table of size . Each cell requires constant time operations (comparison, addition, max). Thus, the total time is proportional to the product of the string lengths. Given constraints , this results in roughly operations, which fits well within standard time limits.
Space Complexity: We allocate a 2D array of size to store the DP states.
The DP - 2D Array pattern with LCS logic is directly applicable to several other hard interview problems:
Why does the naive recursive solution TLE? The naive solution has exponential time complexity because it recalculates the LCS for the same suffixes repeatedly. The DP approach caches these results, reducing complexity to polynomial time.
Why do we need a DP table of size (m+1) x (n+1) instead of m x n?
Using m+1 and creates a "buffer" row and column of zeros representing empty strings. This handles base cases automatically, avoiding complex boundary checks (like ) inside the loops.
n+1if i-1 < 0Can we solve this using a Greedy approach? No. A greedy approach might match the first occurrence of a character, which could prevent a longer sequence of matches later. For example, matching the first 'a' in "abac" with "a" might be suboptimal if the second 'a' allows for more subsequent matches. You must explore all possibilities via DP.
What is the difference between Subsequence and Substring?
This is a critical distinction. A substring must be contiguous (e.g., "abc" in "abcde"). A subsequence maintains relative order but can skip characters (e.g., "ace" in "abcde"). The recurrence relation dp[i][j] = max(...) specifically handles the skipping property of subsequences.