Loading problems...
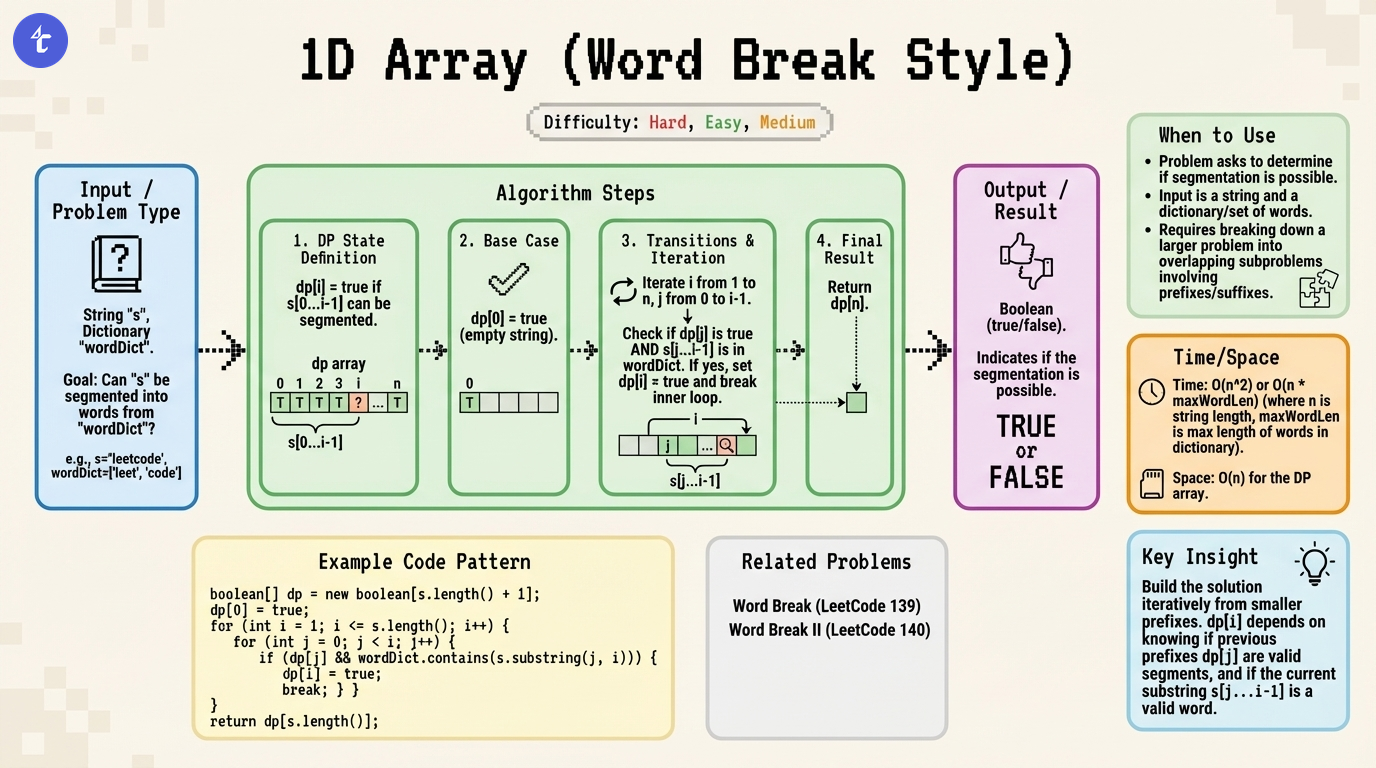
TL;DR: To determine if string s can be segmented, we use a boolean Dynamic Programming array where dp[i] is true if the prefix of length i can be formed by valid dictionary words.
The Word Break problem asks us to determine if a given string s can be completely segmented into a sequence of one or more dictionary words. We are given a non-empty string and a dictionary of unique strings. We may reuse words from the dictionary multiple times. This is a fundamental decision problem often encountered in technical interviews, and the optimal logic relies on breaking the large problem (the full string) into smaller, overlapping subproblems (prefixes).
This guide details the LeetCode 139 Solution using the optimal Dynamic Programming approach.
The naive approach to solving Word Break is to use recursion with backtracking. We attempt to split the string at every possible position. If the prefix s[0...i] exists in the dictionary, we recursively call the function on the remaining suffix s[i+1...n].
The algorithm proceeds as follows:
1 to length.true if any split results in a valid segmentation.python# Pseudo-code for Brute Force def canBreak(s, wordDict): if not s: return True for i from 1 to length(s): prefix = s[0:i] if prefix in wordDict and canBreak(s[i:], wordDict): return True return False
Time Complexity: .
In the worst case (e.g., s = "aaaaa", wordDict = ["a", "aa", "aaa"]), the recursion tree branches at every index. There are possible ways to split a string of length . This exponential growth makes the brute force solution infeasible for the given constraint of s.length <= 300. It will result in a Time Limit Exceeded (TLE) error.
The brute force approach fails because it re-evaluates the same suffixes repeatedly. For example, if we split "leetcode" into "l" + "eetcode" and later "le" + "etcode", we might end up evaluating "code" multiple times through different recursive paths.
The core insight is to store the result of these subproblems. We define a boolean array dp, where dp[i] represents whether the prefix of string s of length i (i.e., s[0...i-1]) can be successfully segmented.
The Invariant:
To set dp[i] to true, we must find a split point j (where 0 <= j < i) such that:
dp[j] is true (meaning the prefix ending at j is valid).s[j...i] exists in the dictionary.If both conditions are met, it implies we can form the prefix of length j using dictionary words, and then append the dictionary word s[j...i] to complete the prefix of length i.
Visual Description:
Imagine a boolean array filling up from left to right. To determine the value at the current index i, we look backward at all previous indices j. If we find a j that was marked "valid" (true) and the segment connecting j to i is a valid word, we mark i as "valid" and stop checking further for this index. We proceed until we reach the end of the string.
Let's trace s = "leet", wordDict = ["le", "et"].
Length n = 4. dp array size is 5.
Initialization:
dp = [T, F, F, F, F] (T=True, F=False)Set = {"le", "et"}i = 1 (substring "l"):
j=0: dp[0] is T. s[0:1] ("l") in Set? No.dp[1] remains F.i = 2 (substring "le"):
j=0: dp[0] is T. s[0:2] ("le") in Set? Yes.dp[2] = T. Break inner loop.dp = [T, F, T, F, F]i = 3 (substring "lee"):
j=0: dp[0] is T. "lee" in Set? No.j=1: dp[1] is F. Skip.j=2: dp[2] is T. s[2:3] ("e") in Set? No.dp[3] remains F.i = 4 (substring "leet"):
j=0: dp[0] is T. "leet" in Set? No.j=1: dp[1] is F. Skip.j=2: dp[2] is T. s[2:4] ("et") in Set? Yes.dp[4] = T. Break.dp = [T, F, T, F, T]Return: dp[4] is True.
The correctness follows by induction.
dp[0] is true because an empty prefix requires no words, satisfying the condition trivially.k < i, dp[k] correctly identifies if the prefix of length k is segmentable. When calculating dp[i], we iterate through all j < i. If dp[i] is set to true, it means there exists a j where dp[j] is true (prefix s[0...j-1] is valid) and s[j...i-1] is a dictionary word. The concatenation of a valid segmented prefix and a valid dictionary word yields a valid segmented prefix of length i.j, if a valid segmentation exists ending at i, we will find it. Therefore, dp[n] correctly determines if the entire string is segmentable.cpp#include <vector> #include <string> #include <unordered_set> class Solution { public: bool wordBreak(std::string s, std::vector<std::string>& wordDict) { // Optimize lookup with a hash set std::unordered_set<std::string> dict(wordDict.begin(), wordDict.end()); int n = s.length(); // dp[i] represents if s[0...i-1] (prefix of length i) is valid std::vector<bool> dp(n + 1, false); // Base case: empty string is valid dp[0] = true; for (int i = 1; i <= n; ++i) { // Check all possible split points j for (int j = 0; j < i; ++j) { // If prefix ending at j is valid AND substring(j, i) is a word // Note: substr length is i - j if (dp[j] && dict.count(s.substr(j, i - j))) { dp[i] = true; break; // Found a valid path for length i, move to next i } } } return dp[n]; } };
javaimport java.util.List; import java.util.Set; import java.util.HashSet; class Solution { public boolean wordBreak(String s, List<String> wordDict) { // Use a HashSet for O(1) lookups Set<String> dict = new HashSet<>(wordDict); int n = s.length(); // dp[i] is true if s.substring(0, i) can be segmented boolean[] dp = new boolean[n + 1]; // Base case dp[0] = true; for (int i = 1; i <= n; i++) { for (int j = 0; j < i; j++) { // Check if prefix s[0...j] is valid and s[j...i] is in dict if (dp[j] && dict.contains(s.substring(j, i))) { dp[i] = true; break; // Optimization: stop checking once true } } } return dp[n]; } }
pythonclass Solution: def wordBreak(self, s: str, wordDict: list[str]) -> bool: # Convert list to set for O(1) lookups word_set = set(wordDict) n = len(s) # dp[i] means s[:i] is a valid segmentation dp = [False] * (n + 1) dp[0] = True for i in range(1, n + 1): for j in range(i): # If prefix s[:j] is valid and substring s[j:i] is in dictionary if dp[j] and s[j:i] in word_set: dp[i] = True break return dp[n]
Let be the length of string s and be the maximum length of a word in wordDict.
Time Complexity: or
The DP - 1D Array (Word Break Style) pattern is versatile. The logic used here—building a solution for index i based on valid split points j—directly applies to:
i (or use backtracking with memoization).s[j:i] is in a dictionary, you check if it is a palindrome.Understanding the invariant of checking all split points j < i is key to solving this family of problems efficiently.
Why does my solution get Time Limit Exceeded (TLE)?
wordDict.i goes from 1 to , and j goes from 0 to i. This gives iterations.s[j:i] and a hash set lookup. Creating the substring and hashing it takes time proportional to the length of the substring, which is in the worst case (or if we optimize by limiting the lookback to the max word length).Space Complexity:
dp array of size .Why is my DP array size n instead of n+1?
dp with size len(s) and trying to map index i to s[i].Why do I get false negatives when the word exists?
substring(start, end) excludes the end index. If you loop j up to i but slice incorrectly, you might miss the last character.false for valid inputs.